
今日看到有許多鐵人賽的朋友紛紛完賽,有點好奇目前還有幾位鐵人還在一起努力,於是想到可以撰寫爬蟲 Web scraper 程式來了解一下,而在 Java library 中有個 JSOUP 套件,此套件有提供許多方便易用的 API 可以解析 HTML,使用方法與 CSS 或 jQuery 選擇器類似,也因為 Kotlin 與 Java 整合度非常好,所以 Kotlin 可以直接呼叫 Java Library 讓我們順利處理許多事情,下面我們來介紹 JSOUP 的使用方式與實作範例「鐵人賽比賽現況」
引入方法
若要使用 JSOUP 套件要記得先引入套件,下面是 Maven 與 Gradle 分別引用方式
Maven
1
2
3
4
5<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>Gradle
1
compile 'org.jsoup:jsoup:1.13.1'
資料輸入方法
JSOUP 主要支援四種輸入(Input)方式進行解析成 Document 物件,如下:
從 字串 解析
此方法要注意字串必須包含 head 與 body 元素
1
2val html : String = "<html><head><title>First parse</title></head>" + "<body><p>Parsed HTML into a doc.</p></body></html>";
val doc : Document = Jsoup.parse(html);從 HTML 片段解析
我們也可以將 HTML Body 元素下的部份元素進行分析,例如一部份的 Div 元素,如下:
1
2
3val html : String = "<div><p>Lorem ipsum.</p>";
val doc : Document = Jsoup.parseBodyFragment(html);
val body : Element = doc.body();利用 URL 載入 Document
此方式應該是最常用的方式,利用網頁 url 直接進行分析,其中會使用到 connect 方法,此方法會我們建立一個新的連線,也可以在此方法設定請求細節,例如 cookie、userAgent、timeout等設定,如下:
1
2val doc : Document = Jsoup.connect("http://example.com/").get();
val title : String = doc.title();利用 File 載入 Document
我們也可以將 HTML 檔案進行讀檔分析,如下:
1
2val input : File = new File("/tmp/input.html");
val doc : Document = Jsoup.parse(input, "UTF-8", "http://example.com/");
資料解析方法
在解析方法中,主要會推薦使用兩種方法,再看大家比較喜歡哪一種方式:
DOM 方法
此方法就是利用
DOM操作的寫法讓我們學習如何在取得的Document物件進行取得元素值Element,範例如下:1
2
3
4
5
6
7
8
9val input : File = new File("/tmp/input.html");
val doc : Document = Jsoup.parse(input, "UTF-8", "http://example.com/");
val content : Element = doc.getElementById("content");
val links : Elements = content.getElementsByTag("a");
for (val link : links) {
val linkHref : String = link.attr("href");
val linkText : String = link.text();
}- 尋找元素方法有以下幾種
[getElementById(String id)]利用 id 進行尋找[getElementsByTag(String tag)]利用 tag 進行尋找[getElementsByClass(String className)]利用 class 進行尋找[getElementsByAttribute(String key)]利用屬性值進行尋找- 也可以使用下面方法找出與元素有關聯的元素
[siblingElements()][firstElementSibling()][lastElementSibling()][nextElementSibling()][previousElementSibling()][parent()][children()][child(int index)]
- 元素細節操作方法
[attr(String key)]利用元素 key 值取得元素屬性[attr(String key, String value)]設定元素屬性[attributes()]取得所有元素屬性[id()],[className()]and[classNames()][text()]取得元素文字資料[html()]取得元素 HTML 資料[tag()]、[tagName()]取得 Tag 資料
- 控制 HTML 元素 與 文字
[append(String html)],[prepend(String html)][appendText(String text)],[prependText(String text)][appendElement(String tagName)],[prependElement(String tagName)][html(String value)]
- 尋找元素方法有以下幾種
選取器方法
此方法類似於
CSS、jQuery的選取器使用方法,如下:1
2
3
4
5
6
7
8val input : File = new File("/tmp/input.html");
val doc : Document = Jsoup.parse(input, "UTF-8", "http://example.com/");
val links : Elements = doc.select("a[href]");
val pngs : Elements = doc.select("img[src$=.png]");
val masthead : Element = doc.select("div.masthead").first();
val resultLinks : Elements = doc.select("h3.r > a");- 選取器(Selector)使用方式
tagname利用 Tag 找到元素,例如 a 元素#id利用 # 符號加上 id 尋找元素.class利用 . 符號加上 class 值尋找元素[attribute]設定元素是否包含某個屬性進行進階條件尋找[attr=value]設定元素是否包含某個屬性欄位與對應值,例如 width=500[attr^=value],[attr$=value],[attr*=value]可針對屬性值使用模糊查詢[attr~=regex]: 針對屬性值使用 regular expression,例如img[src~=(?i)\.(png|jpe?g)]
- 選取器組合(Selector combinations )方式
el#id利用元素加上 id 值進行尋找,例如div#logoel.class利用元素加上 class 值進行尋找,例如div.mastheadel[attr]利用元素搭配屬性值進行尋找,例如a[href]- 或是使用任何元素與屬性進行尋找,例如
a[href].highlight
- 選取器(Selector)使用方式
元素擷取細節
上面已經介紹如何取得 Document 物件與取得特定元素 Element,再來想要介紹如何取得元素Elements 的細節資料,例如元素的文字(Text)、連結(href)等欄位,如下範例:
1 | val html : String = "<p>An <a href='http://example.com/'><b>example</b></a> link.</p>"; |
實作範例
如本文開頭所述,這個範例是想了解鐵人賽還有多少參賽者還在一起努力,有多少鐵人朋友已經順利達陣完成30天目標,故我們從鐵人賽頁面的選手列表進行觀察,我們可以開啟瀏覽器的開發者工具了解網站每個元素的規則,這邊將觀察到的規則整理如下:
(1) 開啟瀏覽器開發者工具,觀察每個元素如何進行命名,找出對應的規則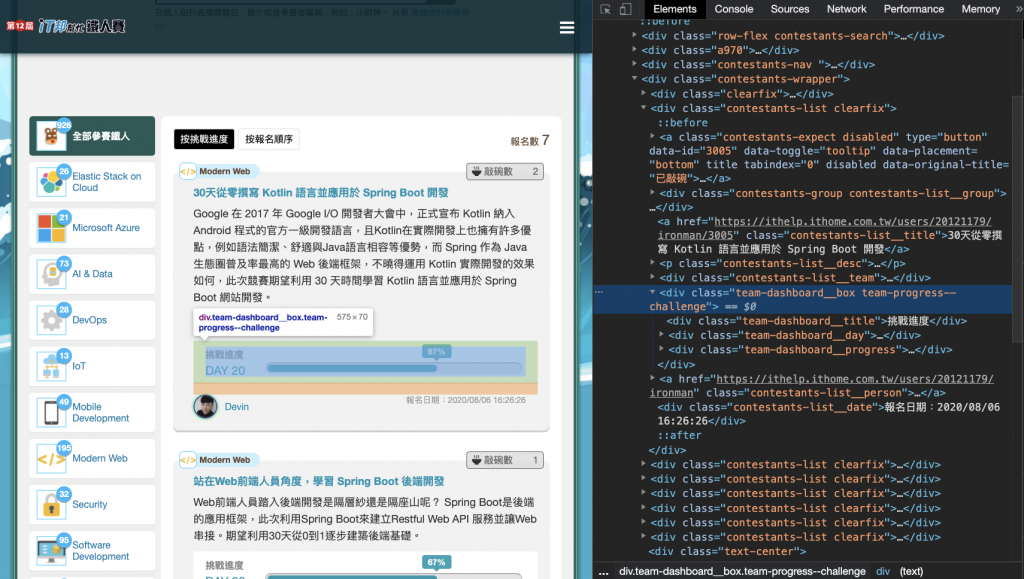
- contestants-list clearfix 為每一個參賽者資料區塊
- contestants-list__title 參賽者參賽主題
- contestants-list__name 參賽者暱稱
- contestants-list__desc 主題描述
- contestants-expect__number 敲碗數
- team-dashboard__day 挑戰天數
- contestants-group contestants-list__group 挑戰組別
- contestants-list__date 報名日期
- team-dashboard__box team-progress–challenge 正在挑戰的樣式
- team-dashboard__box team-progress–fail 挑戰失敗的樣式
(2) 觀察出關鍵元素-正在挑戰 / 挑戰失敗的樣式差異,如下圖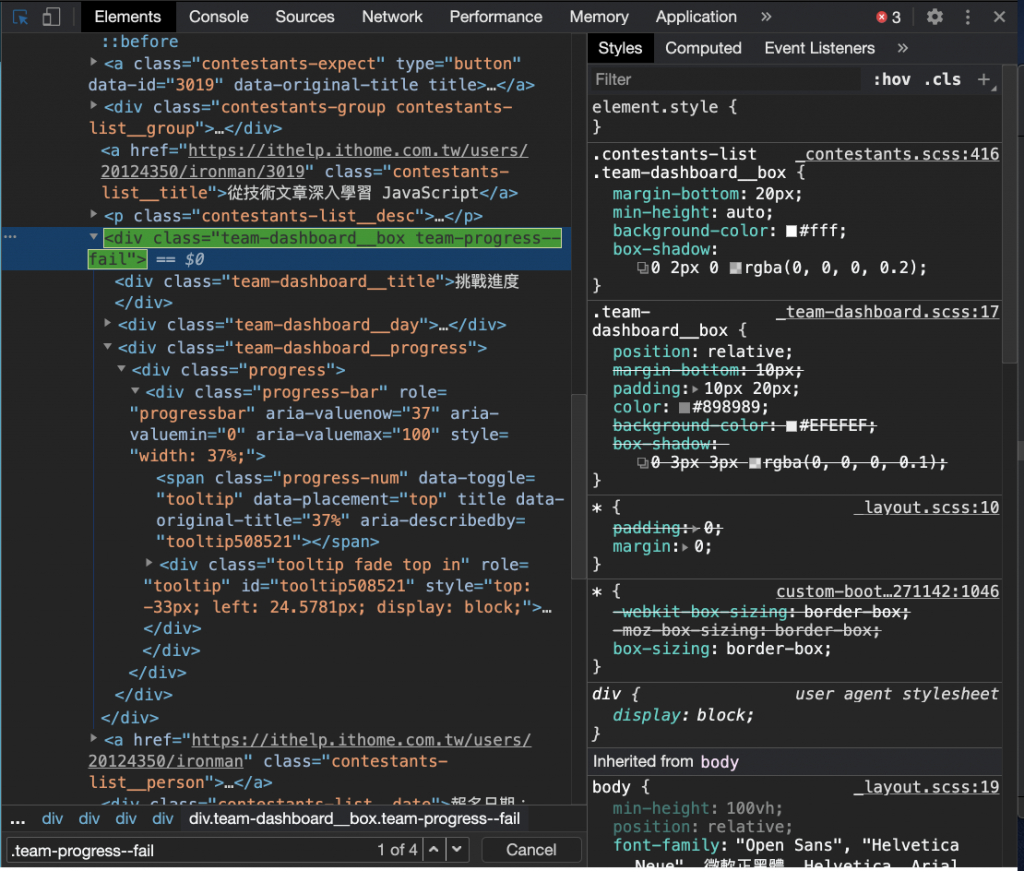
(3) 接下來,我們利用上述整理的規則進行撰寫程式,說明如下:
1 |
|
(4) 接著執行程式 ,會產生如下 API 爬蟲結果:
(5) 接著,當我們完成爬蟲程式並取得資料結果,後續其實就可以做很多事情,像是資料分析、資料視覺化等動作,下面也是我們針對結果產生出圖表,可以從圖表觀察出目前比賽進度的人數比例: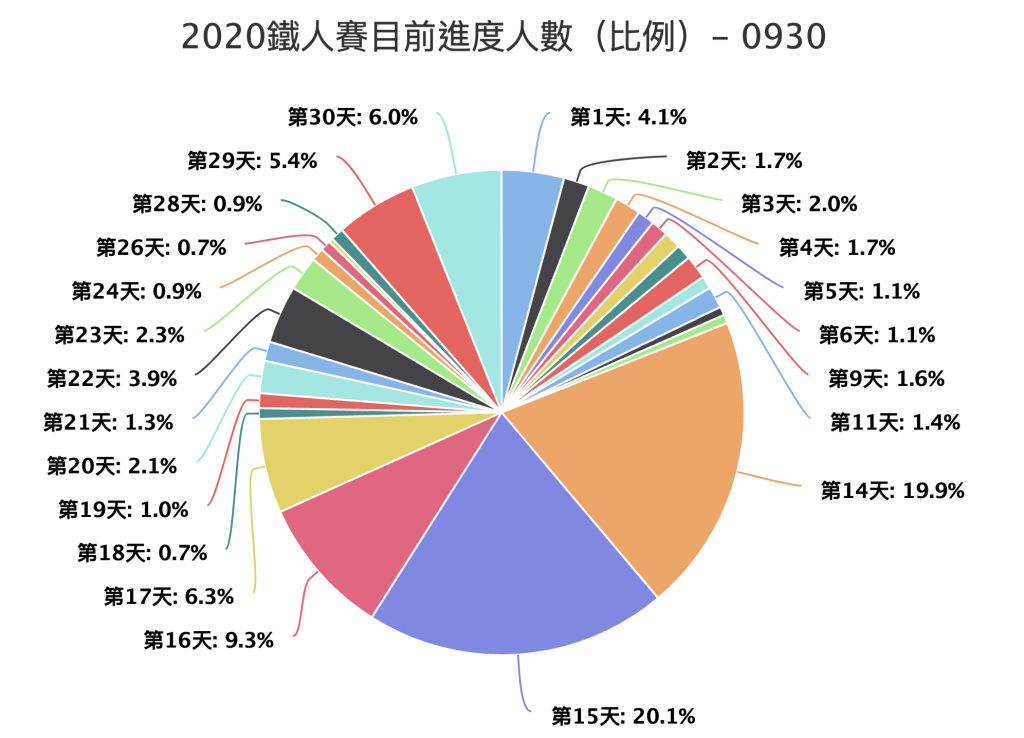
以上是 JSOUP 爬蟲介紹,建議大家可以練習實作看看,爬蟲程式在實作上不難,但卻可以讓我們在後續實作出很多很有趣的應用。
Rerference
- [官方文件] Jsoup cookbook